¿Alguna vez has oído hablar de las D.O.R.A metrics? En los últimos años es un tema cada vez más relevante dentro del sector I.T por lo que me gustaría hablaros sobre ellas.
¿Qué son las D.O.R.A metrics?
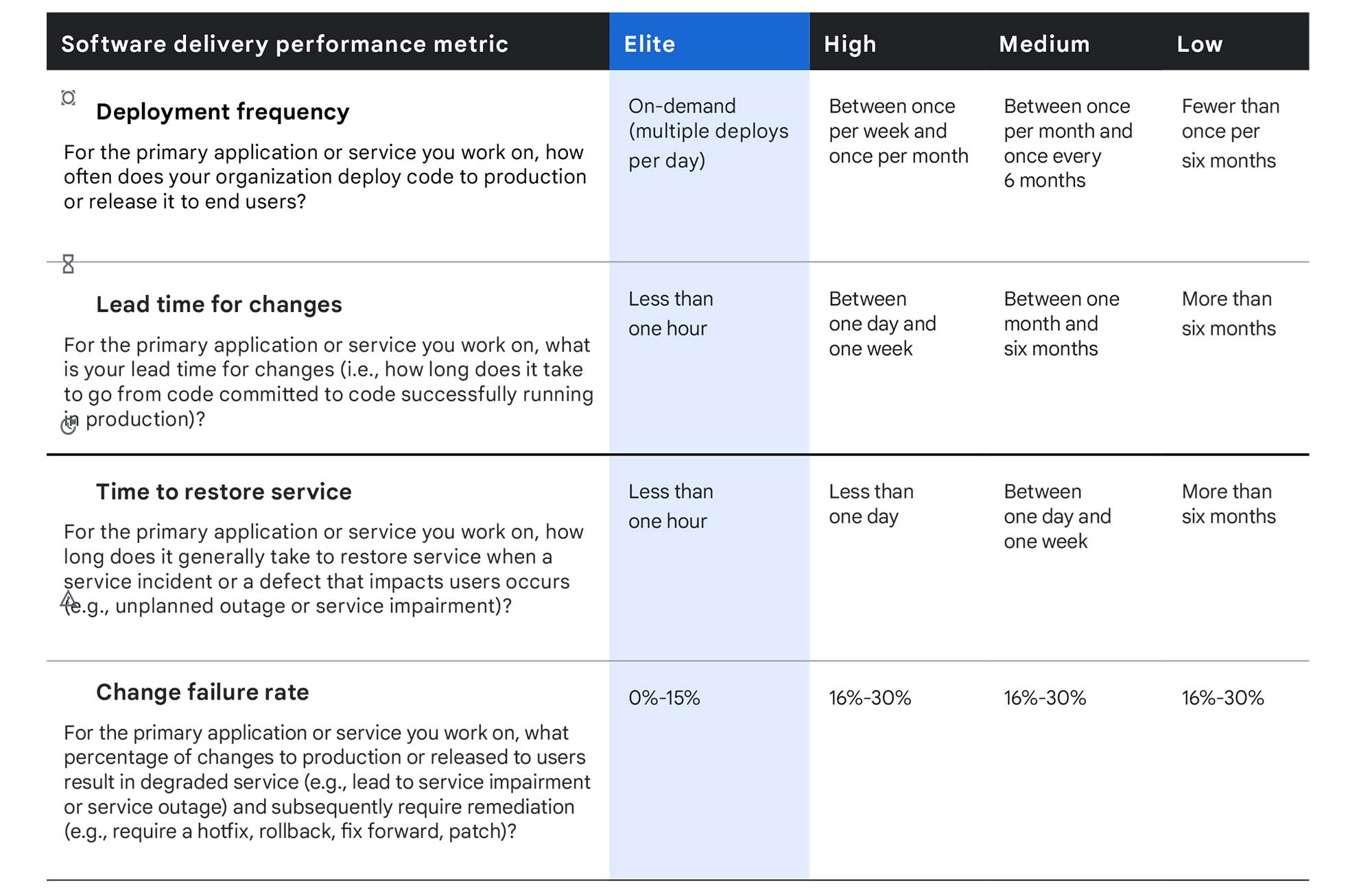
D.O.R.A es el acrónimo de DevOps Research and Assessment un grupo de investigación de Google. Dicho grupo ha definido unas métricas que permiten a los equipos medir y analizar su rendimiento, con ellas en la mano los equipos serán capaces de tomar una serie de medidas tratando de mejorar su rendimiento.
Como veremos a continuación todas estas métricas giran en torno a un objetivo común que es ayudar a los equipos a reducir el tiempo que tardan en llevar cambios a producción, reduciendo la posibilidad de introducir errores y sin perder calidad durante el mismo.
¿Cuáles son las D.O.R.A metrics?
Bien, una vez explicado de forma general que son estas métricas vamos a analizar de forma detallada de cada una de ellas de forma individual.
Deployment Frequency (DF)
¿Cuántas veces despliega tu equipo a producción? ¿Hablamos del rango de semanas? ¿Tal vez días? ¿Horas?. Este intervalo de tiempo es una de las métricas que permite conocer cuán de rápido es capaz un equipo de llevar nuevos cambios a producción.
A lo largo de mi vida laboral he tenido la suerte de trabajar en equipos con todo tipo de rangos, desde una vez cada 15 días al final de un sprint, hasta desplegar cada pocas horas todos los días de forma completamente automática, pasando por despliegues semanales de forma semi-automática.
Que esta métrica DF sea alta será un buen indicador de que los equipos son capaces de entregar valor de forma rápida, lo que implícitamente les permitirá tener un feedback muy rápido por parte de los usuarios.
Por el contrario que esta métrica sea muy baja será un claro indicador de que, o bien, a los equipos les cuesta mucho llevar nuevos cambios a producción o peor aún, los equipos llevan muchos cambios cada mucho tiempo a producción lo que puede convertirse en un caos.
Lead Time for Changes (LT)
¿Trabajas en un equipo donde cada integrante del mismo trabaja de forma asíncrona creando posteriormente un Pull-Request con los cambios para que sean revisados? ¿O por el contrario trabajas en un equipo donde se aplican técnicas como el pair programming donde no existen las Pull-Request y los cambios se llevan directamente a la rama principal?
En función de la forma de trabajar de los equipos esta métrica (LT) tendrás unos valores muy altos (en el orden de semanas trabajando con Pull-Requests) o muy bajos (en el orden de minutos en equipos que trabajen en pair).
Nuevamente que este LT sea alto será un claro indicador de que a el equipo le cuesta mucho entregar valor a los usuarios. Por el contrario un LT bajo indicará que el equipo es capaz de entregar pequeños incrementos de valor a los usuarios consiguiendo un feedback de vuelta muy rápido.
Habiendo vivido en ambos extremos de esta métrica, debo decir que para mí cuanto menos tarde el código en llegar a producción mejor. Por no hablar del sentido de las Pull-Requests en equipos de un tamaño “normal” (menos de 10 personas). Con técnicas como TBD donde no existen las ramas y los cambios se mergean directamente a la rama principal será posible reducir esta métrica drásticamente. Esto se debe a que los equipos en los que se trabaja con ramas es muy habitual que la aprobación de unos cambios por parte del resto del equipo lleve varios días, incluso semanas, mientras que son TBD esta fase directamente no existe.
Change Failure Rate (CFR)
Las dos primeras métricas buscan reflejar cómo de rápido puede entregar valor un equipo, está en cambio nos va a permitir conocer cómo de fiables son los cambios que el equipo lleva a producción.
Estaréis de acuerdo conmigo que de nada vale que un equipo despliegue cientos de veces a la semana si estos despliegues introducen fallos que obligan a hacer rollbacks continuos para corregir estos fallos. Tan importante para un equipo es ser capaz de entregar valor en ciclos los más cortos posible, como hacerlo sin perder calidad en el proceso.
Un CFR alto será un claro indicador de que el equipo no está validando correctamente los cambios. También es posible que los fallos se produzcan por una mala infraestructura (y que no tengan nada que ver con el código propiamente dicho), por lo que esta métrica nos permitiría detectar este tipo de situaciones.
De forma opuesta un CTR bajo será un indicador de que el equipo trabaja de forma segura, con buena calidad y utilizando de forma eficiente los recursos.
Existen diferentes formas de mejorar esta métrica aplicando conceptos como el TDD, una técnica de diseño de software que nos va a permitir tener una confianza muy alta sobre lo que hace nuestro código y evitará gran parte de los fallos actuales en producción.
Mean Time to Recover (MTTR)
Seguro que alguna vez has vivido un despliegue a producción en el que algo sale mal y es necesario volver a la versión anterior. Este proceso conocido como rollback y dependiendo del equipo el tiempo requerido para restaurar una versión anterior puede variar desde el rango de segundos a incluso horas.
Un MTTR bajo indicará que el equipo dispone de un proceso de rollback sencillo y rápido que le permitirá revertir un fallo en producción de forma casi instantánea. Por el contrario un MTTR alto sería un claro indicador de que para el equipo cada despliegue será un momento crítico con de mucha presión por si sale algo mal.
Mi propia experiencia me dice que un tiempo de rollback bajo alivia mucho la presión que sienten los equipos a la hora de desplegar cambios, lo que les lleva a desplegar lo mínimo posible.
Una técnica que a mí me gusta mucho es tener unos tests de regresión que se lanzan automáticamente después de cada despliegue y que comprueban los principales comportamientos de nuestra aplicación. Si algo sale mal de forma completamente automática se realiza un rollback a la versión anterior. Esta aproximación permite a los equipos ganar mucha confianza lo que les animara a incrementar el número de despliegues de forma inconsciente.
¿Por qué son relevantes las D.O.R.A metrics?
La existencia de estas métricas es muy importante, ya que permite valorar de forma estandarizada y objetiva cuál es el estado de los equipos en lo que respecto a su fase de desarrollo. Previamente esta valoración, al no tener este tipo de métricas, era muy subjetiva, lo que hacía que algunos equipos pensarán que todo estaba bien dentro de sus equipos de ingeniería cuando la realidad era bastante distinta.
Lograr unas buenas métricas será un gran indicador para los equipos en lo que se refiere a una entrega de valor más frecuente, con mayor calidad y en el menor tiempo posible. Algo que sin duda es un indicador super positivo para cualquier equipo de ingeniería.
Conclusiones
Después de conocer qué son y porque son interesantes estas métricas me gustaría acabar diciendo que debemos acercarnos a ellas con mucha cautela, sin ningún tipo de presión u obligación.
Muchas veces como ingenieros nos tomamos las cosas demasiado en serio llegando a obsesionados buscando una perfección en algo que ya es lo suficientemente bueno, cuando para nada debería ser así.
De igual forma unas malas métricas no son un indicativo de que el equipo sea peor que otro con mejores métricas, ni mucho menos. Cada empresa es un mundo y el contexto siempre es más importante que todo esto que hemos hablado.
Lo importante es saber que existen este tipo de métricas para acercarnos a ellas con interés y quedarnos con lo que nos aporte valor.
!Un saludo!