Últimamente, he tenido la oportunidad de trabajar más cerca de la infra, tanto creando como manteniendo la misma.
Siendo una persona con un perfil claramente de desarrollo tenía cierta preocupación respecto a la aplicación de buenas prácticas en IaC (Infrasctructure as Code). Por suerte existen grandes opciones para trabajar Lean, en baby steps, pre-commits y con una pipeline muy potente que nos sirva de red de seguridad.
Terraform 101
A día de hoy creo que no hay ninguna duda que la mejor forma de manejar nuestra infra es mediante código, aplicando las buenas prácticas que ya han demostrado en el desarrollo más tradicional que suelen dar buenos resultados a la hora de mantener y extender el código a lo largo del tiempo.
Para ello Terraform no tiene rival, ya que es el más extendido, es muy fácil de integrar en nuestras pipelines, tiene una gran cantidad de “plugins” y una comunidad muy activa detrás.
A continuación veremos sus principales componentes.
Providers
Para poder interactuar con nuestra infraestructura es necesario configurar en acceso los servicios de la misma (AWS, GitHub, Mongo, etc.), a grandes rasgos estos actores son:
- Cada
providerañade un conjunto de tipos de recursos y/o fuentes de datos que Terraform puede gestionar. - Cada recurso tiene un
providerasociado y está implementado por este mismo.- Harshicorp (empresa detrás de Terraform) proporciona algunos AWS, Azure, Google Cloud, etc.
- El registro de Terraform es el lugar principal donde se pueden encontrar los
providersde Terraform públicamente disponibles. - Cada
providertiene su propia configuración.
provider "aws" {
...
}
provider "github" {
...
}
provider "mongodbatlas" {
...
}
Aquí tenemos una lista de todos los providers disponibles.
Data Sources
Dichos providers nos permiten interactuar con los recursos de la infraestructura, pero también podemos acceder a información
definida fuera de Terraform.
Para ello haremos uso de los bloques data:
- El block
datase usa para definir un recurso de tipo Data Source. - El tipo de
datajunto con su nombre sirven como identificador de un recurso dado y, por lo tanto, deben ser únicos dentro de un módulo. - Estos bloques son solo de lectura, nunca crean infra.
- Dichos
providersnos permiten interactuar con los recursos de la infraestructura, pero tambien podemos acceder a informacion definida fuera de Terraform.
# Read AWS Zone
data "aws_route53_zone" "my_zone" {
...
}
# Read AWS Policy document
data "aws_iam_policy_document" "role_assume_my_new_role" {
...
}
Aquí podemos ver los Data Sources de AWS.
Resources
En el caso de necesitar crear nueva infraestructura, los resources son los bloques indicados para ello. Sus principales características son:
- Cada recurso puede describir uno o más objetos de infraestructura.
- El bloque
resourcese usa para declarar un recurso de un tipo específico con un nombre local específico. - El conjunto
resourcey nombre del recurso debe ser único.
# Create a Github repository
resource "github_repository" "my_new_repository" {
...
}
# Create a new Github team
resource "github_team" "my_team" {
...
}
Aquí podemos ver los Resources de GitHub.
Importar recursos
A veces es necesario importar infraestructura ya existente dentro de nuestro código para poder empezar a
gestionarla. Para ello existe el bloque import que nos hará la vida mucho más sencilla.
Las principales para importar un recurso son:
- Requiere el ID del recurso a importar.
- Este cambio en cada tipo de recurso.
- El bloque
resourcedebe estar definido antes de importar el recurso y debe coincidir con lo importado. - También existe la posibilidad de que Terraform nos genere el codigo automaticamente (más info aquí si queremos ahorrarnos algo de tiempo).
- Estos imports se deben borrar una vez que el estado ya gestiona el recurso.
# Import one exisiting bucket in our state
import {
id = "my-bucket"
to = aws_s3_bucket.my_bucket
}
resource "aws_s3_bucket" "my_bucket" {
...
}
Aquí tenemos documentado como se importaría in role de AWS.
Pre-commit hooks
Una vez hablado muy por encima de Terraform vamos a ver como podemos mejorar la experiencia de desarrollo o la vez que aseguramos una calidad minima en nuestro codigo.
Si pensamos de más cerca a más lejos del desarrollador , es decir ‘Local -> CI/CD -> Producción’, es muy interesante si conseguimos que el fallo se produzca lo más rápido y cercano posible de desarrollador. De esta forma nos evitamos tener que cambiar el contexto, ir a la pipeline y verla fallar. Además de evitar commitear código roto.
Para ellos vamos a hacer uso del pre-commit hook de Git, que nos permiten ejecutar comandos antes de cada commit.
Los pasos son muy sencillos:
-
Creamos un script para instalar el hook en el proyecto:
#!/bin/bash set -e function install_git_hooks { echo "Installing git hooks..." git config core.hooksPath scripts/hooks } install_git_hooks -
Creamos el propio hook que hace uso de Make y de la librería pre-commit
#!/bin/bash set -e exec < /dev/tty make pre-commit -
Creamos el makefile para facilitar este tipo de tareas:
.DEFAULT_GOAL := help .PHONY: help help: ## Show this help. @grep -E '^\S+:.*?## .*$$' $(firstword $(MAKEFILE_LIST)) | \ awk 'BEGIN {FS = ":.*?## "}; {printf "%-30s %s\n", $$1, $$2}' .PHONY: local-setup local-setup: ## Set up the local environment (e.g. install git hooks) scripts/local-setup.sh .PHONY: pre-commit pre-commit: pre-commit run --all-files -
Por último, creamos un fichero
.pre-commit-config.yamldonde definiremos que queremos validar en el pre-commit:repos: - repo: https://github.com/pre-commit/pre-commit-hooks rev: v4.5.0 hooks: - id: detect-aws-credentials name: Detect-aws-credentials - id: detect-private-key name: Detect-private-key - repo: https://github.com/antonbabenko/pre-commit-terraform rev: v1.86.0 hooks: - id: terraform_fmt name: Terraform fmt. files: .+\/.+\/.+ - id: terraform_validate name: Terraform validate. files: .+\/.+\/.+
Lista completa todos los hooks disponibles aquí
Ya solo bastaría con ejecutar make local-setup para instalar los hooks y a partir de ese momento todos los commits lanzaran el hook.
CI/CD pipeline
Alejándonos un poco del desarrollador y acercándonos más a nuestra infra, vamos a ver como podemos integrar Terraform en nuestra pipeline de CI/CD y así gestionarla de una forma segura y muy cómoda.
Pero antes vamos a pensar un poco en una situación bastante habitual.
Imagina que alguien del equipo hace cambios directamente en producción sin reflejarlos en un repositorio. El código, por tanto, ya no refleja el estado actual de la infraestructura, así que cuando llegas tu detrás y te pones a hacer cambios que no tienen nada que ver con los anteriores te encuentras que la infra real no se corresponde con lo que ves en código.
¿Vaya mal cuerpo no? Yo lo he vivido y dan sudores fríos.
Tenemos que evitar este tipo de prácticas por todos los medios, para ello algunos consejos:
- La pipeline debe ser la única fuente de la verdad y el único punto donde se aplican cambios.
- No se aplican cambios en local nunca.
- Si la infra no se corresponde con el código, el código es lo que manda y se debería aplicar de nuevo (obviamente previo aviso y con un periodo de gracia corto).
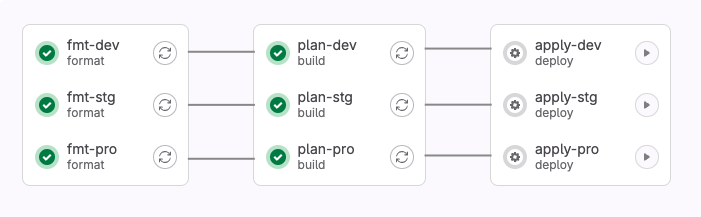
A continuación os dejo un ejemplo muy sencillo de como podríamos tener una pipeline de Terraform en Gitlab. Dicha pipeline
solo tiene un entorno y sigue una secuencia muy habitual de Lint -> Plan -> Apply.
include:
- template: Terraform/Base.latest.gitlab-ci.yml
variables:
TF_ROOT: ${CI_ENVIRONMENT_NAME}
fmt-dev:
extends: .terraform:fmt
variables:
TF_STATE_NAME: dev
allow_failure: false
environment:
name: dev
plan-dev:
extends: .terraform:build
variables:
TF_STATE_NAME: dev
environment:
name: dev
needs: ["fmt-dev"]
apply-dev:
extends: .terraform:deploy
variables:
TF_STATE_NAME: dev
environment:
name: dev
needs: ["plan-dev"]
Aquí podeis ver el contenido completo del template proporcionado por Gitlab.
Format - Plan - Apply
Como decíamos la secuencia de la pipeline es muy sencilla y se basa en tres sencillos pasos:
- Primero validamos el correcto formato de nuestros ficheros.
- Si todo va bien hacemos un
terraform planpara ver qué cambios se van a aplicar. - Si los cambios son correctos, aplicamos los cambios con
terraform apply.
Con esto conseguimos:
- Nuestro código siempre va a estar bien formateado y todo el mundo usará el mismo estilo.
- Cada push a master es una nueva pipeline donde se ejecuta el plan siempre.
- El apply se ejecuta manualmente.
- El rollback es muy rápido y sencillo de hacer, bastaría con hacer revert del commit y aplicar los cambios.
Con esto ya tenemos una pipeline de Terraform básica, pero muy potente y segura. ¡Espero que os haya gustado!