Uno de los ejercicios más habituales durante los procesos de selección es implementar una caché. Hoy vamos a ver un par de formas posibles de hacerlo!.
¿Qué es un caché de tipo LRU?
LRU son las siglas the Least recently used o lo que es lo mismo Menos Usado Recientemente.
Es una caché que se caracteriza por tener una capacidad máxima donde se borran los elementos más antiguos cuando se llena, generando así espacio para nuevos elementos dentro de la misma.
El algoritmo de esta caché es bastante sencillo:
- Se busca dentro de la caché un elemento, si este no existe se debe insertar.
- La caché tiene una capacidad máxima.
- Si la caché se llena se debe borrar los elementos que llevan más tiempo sin leer.
- Cuando se lee un elemento de la caché, este pasa a ser el leído más recientemente dentro de la misma.
Implementación no óptima
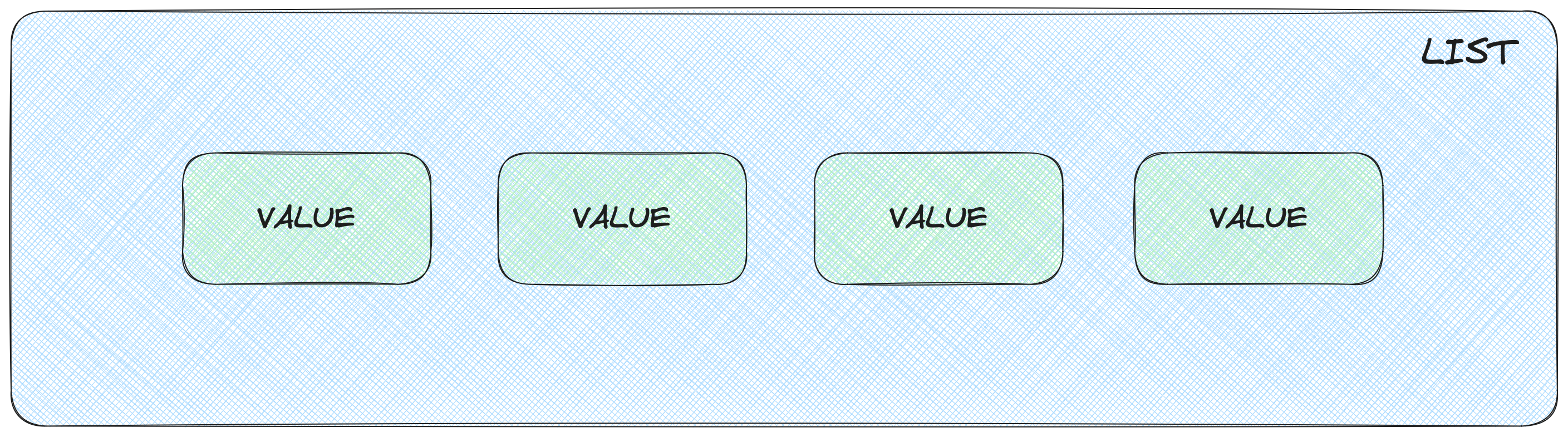
Si empezamos por la implementación más sencilla, y también menos óptima, solo necesitamos los siguientes componentes:
- Un diccionario que hará las veces de caché propiamente dicha.
- Una lista donde almacenaremos los elementos de la caché en orden de su último acceso.
Este tipo de caché funciona perfectamente para tamaños de caché moderados, pero en cuanto esta caché creciera los tiempos de acceso serían bastante pobres. Esto se debe a que estamos usando una lista donde las operaciones de inserción y borrado de un elemento son bastante lentas.
No quiero entrar mucho en el tema de la complejidad, pero se suele decir que de media estas operaciones
tienen una complejidad de O(N).
Aquí podemos una implementación de este tipo de lista.
Implementación óptima
Para obtener un mejor rendimiento para tamaños de caché grandes tendremos que optar por otro tipo de lista, en nuestro caso vamos a implementar una DoublyLinkedList.
Este tipo de lista compleja se caracteriza porque contiene una serie de elementos llamados nodos, los cuales conocen además de su valor cuáles son sus vecinos.
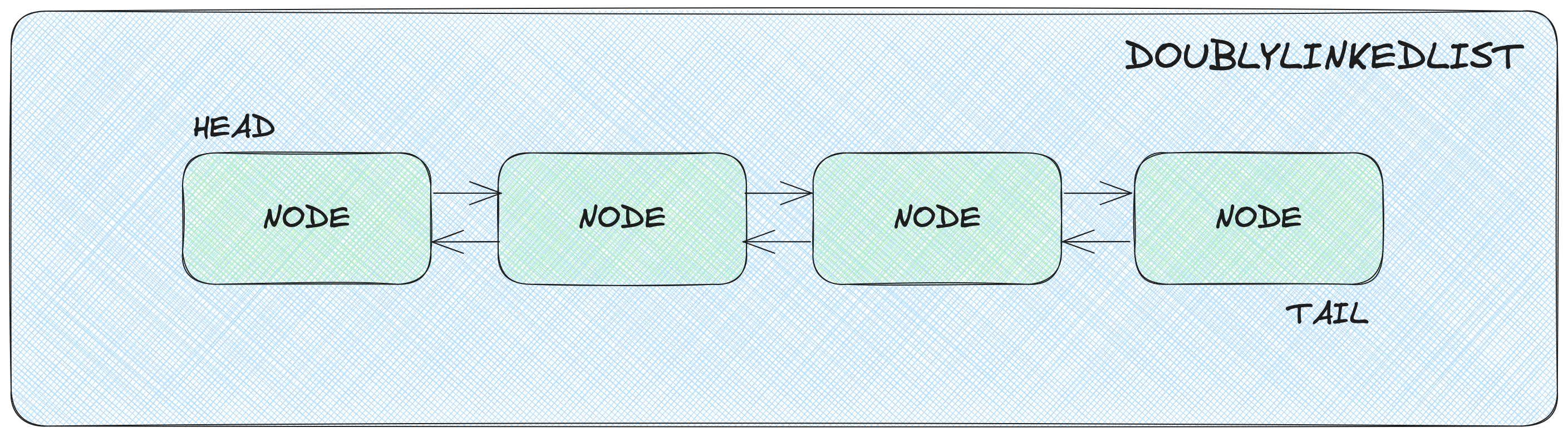
Estos nodos son muy sencillos de implementar, ya que no dejan de ser Value Objects:
class Node
attr_accessor :value, :previous, :next
def initialize value
@value = value
@previous = nil
@next = nil
end
end
La parte interesante de este tipo de lista es que todas las operaciones sobre ella tiene un rendimiento enorme. Tanto si queremos insertar como borrar un elemento lo único que tenemos que hacer es cambiar las referencias de los nodos.
Hilando con lo comentado para la implementación anterior, este tipo de lista tiene una complejidad media de O(1).
Conclusiones
Espero que te haya gustado este ejercicio, si quieres saber más sobre esta implementación óptima, aquí puedes echarle un ojo.
¡Nos vemos en la próxima!